LLM and Token Costs: Essential Knowledge for Biomedical Researchers
For non-members, please read the article here


If you’re eager to integrate LLMs into your workflow to streamline writing research papers, grant applications, or even developing specialized biomedical apps, there’s no escaping two essential concepts: APIs (Application Programming Interfaces) and tokens. Understanding these terms — and their associated costs — can save you headaches (and your budget) later. So buckle up and let’s dive in, but don’t worry — I promise to keep this tech talk friendly and entirely digestible!
What Exactly is an API?
Let’s begin with APIs, which might sound intimidatingly technical, but can easily be understood through a simple metaphor. Think of an API as the waiter at your favorite restaurant:
- You are the user or the app needing information.
- The kitchen represents the backend system (like a database or server) providing the data or service.
- The waiter (API) is the intermediary who takes your order (request), communicates it to the kitchen, and returns with your meal (response).
Imagine you want to check today’s weather forecast on your phone. The weather app uses an API to ask a weather database (the kitchen) for information, then the API (waiter) delivers the weather details back to your phone screen. Similarly, when building automation workflows or apps, your program sends prompts to an LLM via an API, receiving responses directly into your software, eliminating tedious manual interactions with platforms like ChatGPT’s web interface.
Tokens Explained: Welcome to the AI Amusement Park!
Now onto “tokens.” Think of these as amusement park tokens, required for each ride:
- Riding a merry-go-round might cost you 1 token.
- Thrilling roller coasters require 5 tokens.
- Watching a stunning 3D movie might cost 3 tokens.
Each ride has a specific token “cost,” typically higher for more complex or exhilarating experiences. Similarly, in the AI or GPT universe:
- Tokens represent these “amusement park tickets.”
- Every word, punctuation mark, or partial word requires a certain number of tokens.
- A short sentence might use just a few tokens, while longer documents or complex sentences could use hundreds or thousands.
Why Charge with Tokens?
Using tokens is much like buying amusement park tickets upfront instead of paying separately at each attraction. This system has several benefits:
- Easy Pricing: Tokens provide a standard unit to measure different services’ costs.
- Flexibility: You can allocate tokens according to your specific needs.
In ChatGPT or similar LLM services:
- The greater the number of tokens, the more computing resources (like processing power) the AI consumes, making costs higher.
- Typically, fees are calculated based on the total tokens used, combining your input (prompt) and the AI’s output (completion).
Quick Recap on Tokens:
- Tokens are essentially “AI tickets”: the longer and more complex your request or the AI-generated response, the higher your token cost.
- AI services like ChatGPT usually charge based on total tokens used in each interaction.
- Curious to know exactly how your text breaks down into tokens? Visit OpenAI’s tokenizer.
A Practical Example: How Much Does Processing a Scientific Article Cost?
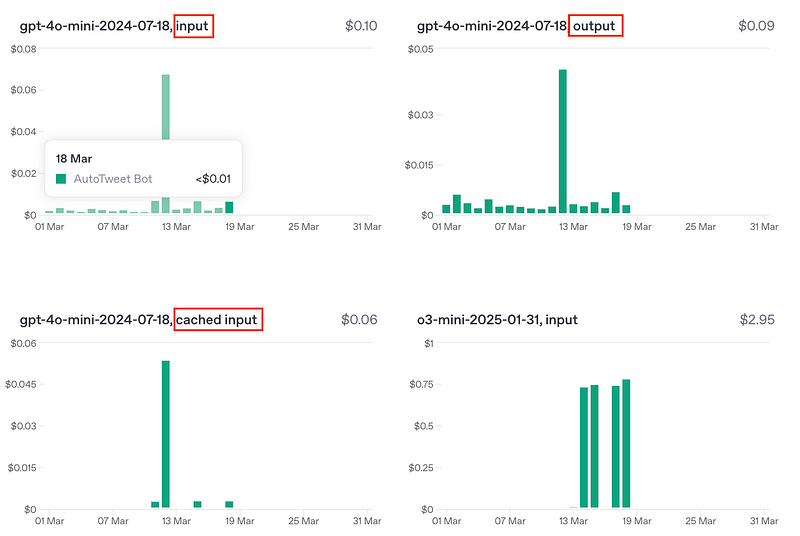
Let’s take an example: Suppose you have a paper from Science Translational Medicine containing about 10,000 words (excluding references and unrelated content). I recently used the ChatGPT (model: 4o-mini) API to summarize, analyze, and extract key points from such an article.

The total cost was impressively low — less than $0.03 — split into three components: input tokens, cached input tokens, and output tokens.
Yes, you read that correctly: just a few cents!
Comparing Costs Across ChatGPT Models: Pick Wisely!
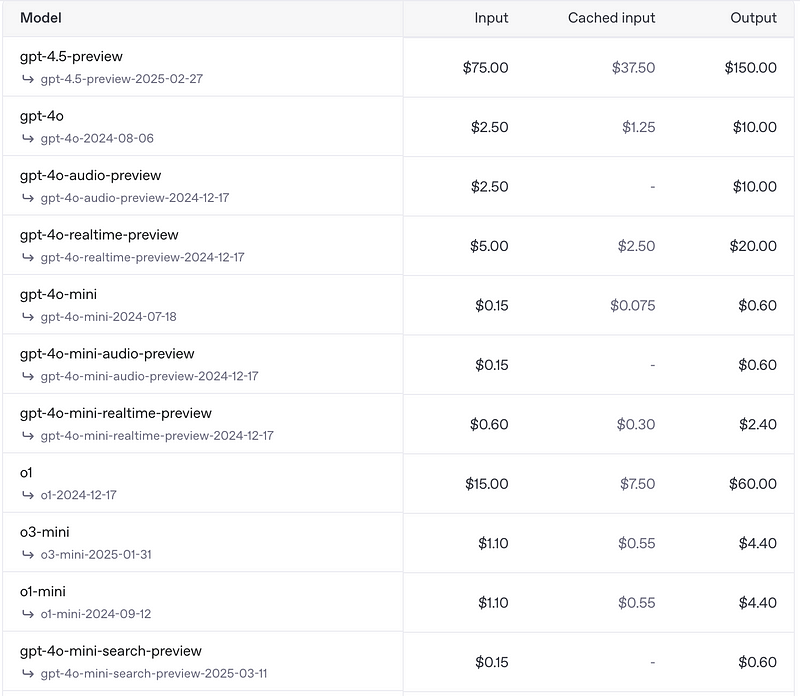
It’s important to understand the pricing differences between various ChatGPT API models. Take a look at these stark contrasts:
- Budget-Friendly Option (4o-mini): Only $0.15 per million tokens of input.
- Premium Options:
- 4o-realtime: $5 per million tokens.
- 4.5-preview: A whopping $75 per million tokens!
You’ll also notice that generating output tokens (AI responses) is significantly more expensive than input tokens. Thus, optimizing and carefully managing your prompts to control the length and complexity of AI outputs becomes crucial when building apps or automated workflows.
What’s Next? Cost Optimization and Workflow Tools
In upcoming articles, I’ll dive deeper into optimizing token usage, cost-effective API strategies, and how to select the right automation tools and models based on your specific research needs and budget. Whether you’re generating professional-grade research reports, crafting complex biomedical documents, or even preparing grants, understanding token economics will be your best ally in managing costs efficiently.
Ready to Dive Deeper?
If you’re excited about leveraging APIs and AI tools to revolutionize your research efficiency and want personalized advice or AI-generated scientific content, feel free to message me directly. I’m eager to hear about your projects and assist you on this AI-driven biomedical research journey!
Remember to subscribe and follow along for more insights, tips, and a bit of laughter as we navigate the thrilling intersection of biology, AI, and automation together.
Happy researching — and careful with those tokens!



